I have two main solutions (and a bunch of derivatives) and this is the harder one of them (i.e. there’s an easier solution, which also happens to be faster).
Spoiler
It looks like you used knot-tying to avoid traversing the list twice, which is pretty sweet! But I think mine's a little easier to wrap one's head around. I wonder if an optimized `lazyReverse` exists that has the benefits of your approach?
This is pretty much my “easier” solution, except mine merges reverse into toList and lazy into foldr. I.e. same idea, just a tad different implementation.
Attribute grammars do let you separate the reversing and the monadic folding, but I don’t think UUAGC can handle the polymorphism that would be necessary and it has quite a bit of sytactic overhead:
data Root
| Root xs :: List
data List
| Nil
| Cons
hd :: {Int}
tl :: List
-- reversing
attr List
syn reversed :: {List}
inh reversedPrefix :: {List}
sem List
| Nil lhs.reversed = @lhs.reversedPrefix
| Cons tl.reversedPrefix = Cons @hd @lhs.reversedPrefix
-- computing
attr List
inh q :: {List}
attr Root List
inh f :: {Int -> Int -> Either Int Int}
syn res :: {Int -> Either Int Int}
sem List
| Nil lhs.res = pure
| Cons (Cons loc.x tl.q) = @lhs.q
lhs.res = \z -> @lhs.f @loc.x z >>= @tl.res
sem Root
| Root xs.reversedPrefix = Nil
xs.q = @xs.reversed
{
foldrM :: (Int -> Int -> Either Int Int) -> Int -> List -> Either Int Int
foldrM f z xs = res_Syn_Root (wrap_Root (sem_Root (Root xs)) (Inh_Root f)) z
}
While lazyReverse solves the challenge, one might reasonably note that its behaviour is perhaps semantically questionable, in that it purports to return a reversal of a infinite list, but no such reversal exists:
λ> z :: Integer; z = 0
λ> length $ take 42 $ lazyReverse [z..]
42
And by all rights foldrM for an infinite list should diverge, regardless of whether the fold operator is lazy in all its arguments.
It should diverge, because not making it diverge has a cost – while very rarely providing a benefit.
If making foldrM fully lazy didn’t incur a cost (or incurred a tiny one), it should’ve been made fully lazy, because introducing pointless strictness is, well, pointless.
That said, there’s more to designing a foldrM than whether it always traverses the entirety of the list or not, in particular
how >>=s are associated
whether the intermediate results are forced or not
I believe if the answer to 1 is “left”, then the answer to 2 should be “yes” and if the answer to 1 is “right” then the answer to 2 should be “no”. See this discussion for a similar problem.
The definition in base is “left” and “no” instead, which doesn’t make any sense to me, but that’s my normal experience when it comes to trying to understand how such decisions are made in Haskell in general.
And the choice for 1 is naturally “left”, because that’s what gives us right-associative construction of the result of the computation. Which matches your observations about base below.
For 2 I’d like to ask what level of strictness you’re looking for?
A strict bind even if the underlying Monad is lazy?
Or, in addition forcing of the value passed to the next stage of the computation?
As noted, yes “left”, which is the natural choice. As for “no”, indeed the values are not forced:
λ> import Data.Foldable
λ> foldrM (\e acc -> Just undefined) 0 []
Just 0
λ> x = foldrM (\e acc -> Just undefined) 0 [0..10]
λ> case x of { (Just _) -> 1 ; Nothing -> 0 }
1
λ> x
Just *** Exception: Prelude.undefined
The undelying definition (unsurprisingly via a left fold of the input) is:
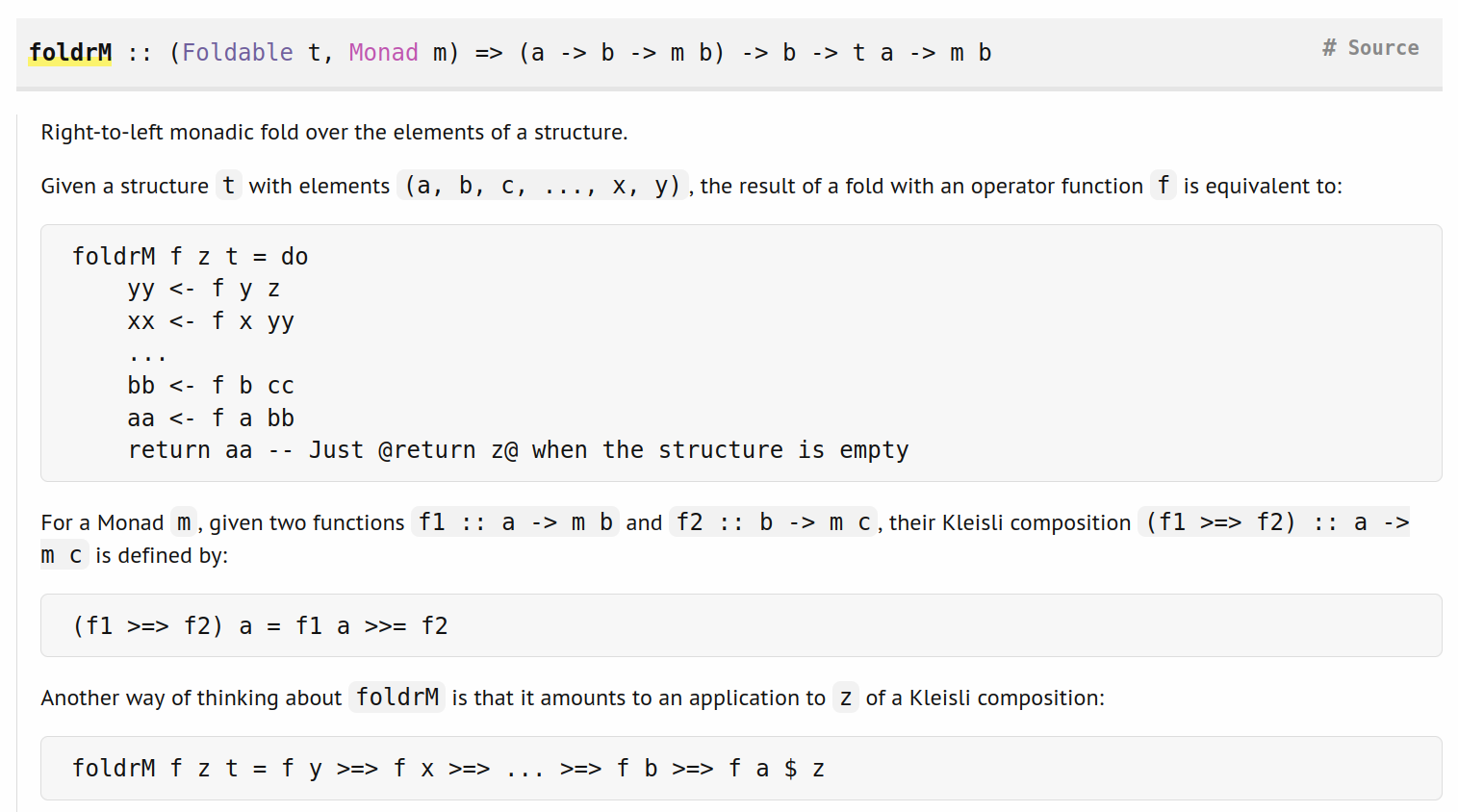
foldrM :: (Foldable t, Monad m) => (a -> b -> m b) -> b -> t a -> m b
foldrM f z0 xs = foldl c return xs z0
-- See Note [List fusion and continuations in 'c']
where c k x z = f x z >>= k
{-# INLINE c #-}
Linear space seems unavoidable, since evaluation starts at the tail of the list. The difference is it seems then just constant factors. Are you suggesting replacing the above with something like:
foldrM :: (Foldable t, Monad m) => (a -> b -> m b) -> b -> t a -> m b
foldrM f z0 = foldr (\ x a -> a >>= \ !acc -> f x acc) (pure z0)
Which does seem to incur less GC overhead for example usages such as:
main :: IO ()
main = print $ foldrM g 0 [0..10000000]
where
g :: Int -> Int -> Maybe Int
g !e !acc = let !s = e + acc in Just s
And, FWIW, I am seeing better performance, and even non-divergence for infinite lists with the lazy State Monad with:
foldrM f = foldr ((=<<) . f) . pure
Example code:
module Main where
import Control.Monad.State.Lazy
foldrM :: (Foldable t, Monad m) => (a -> b -> m b) -> b -> t a -> m b
foldrM f = foldr ((=<<) . f) . pure
main :: IO ()
main = print $ take 10 $ execState (foldrM go () [0..]) []
where
go x _ = modify (x :)
The +RTS -s output is:
52,920 bytes allocated in the heap
3,272 bytes copied during GC
44,328 bytes maximum residency (1 sample(s))
25,304 bytes maximum slop
6 MiB total memory in use (0 MiB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 0 colls, 0 par 0.000s 0.000s 0.0000s 0.0000s
Gen 1 1 colls, 0 par 0.000s 0.000s 0.0004s 0.0004s
INIT time 0.000s ( 0.000s elapsed)
MUT time 0.001s ( 0.000s elapsed)
GC time 0.000s ( 0.000s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 0.001s ( 0.001s elapsed)
%GC time 0.0% (0.0% elapsed)
Alloc rate 101,763,751 bytes per MUT second
Productivity 42.2% of total user, 23.7% of total elapsed
As you’ve already discovered yourself, there’s no reason to use a left fold there, it’s nothing but an unnecessary indirection making things worse.
Almost. I’d introduce this one (left/yes) under the name of foldrM' and fix the current one to be right/no (I didn’t think about any concrete definition, although one of the solutions to my challenges might be good enough).
Except I’d perhaps make it something along the lines of
foldrM' :: (Foldable t, Monad m) => (a → b → m b) → b → t a → m b
foldrM' f z0 = foldr (\ x a → a >>= f x >>= (pure $!)) (pure z0)
(plus the usual Note [List fusion and continuations in 'c'] business)
This way you get both strictness of intermediate results (i.e. on your way back) and laziness in the accumulator as you move forward, making your lazy State example work as well.
And where performance matters >>= is supposed to be inlined anyway turning the >>= (pure $!) part into just a seq call, so if the user is reaching for foldrM’ it’s reasonable to expect that they want performant code and are making sure it is indeed performant.
Yes, even your “naive” version
foldrM :: (Foldable t, Monad m) => (a -> b -> m b) -> b -> t a -> m b
foldrM f = foldr ((=<<) . f) . pure
is vastly superior to the beautifully symmetrical foldl-based one in base.
I feel obligated to mention that, modulo reversing the list, the data flow of the >>= operators is fixed by contracts of foldlM and foldrM.
foldrM f z [a, b, c] = f a =<< f b =<< f c z
foldlM f z [a, b, c] = f a z >>= f b >>= f c
The associativity is then naturally the associativity of the corresponding >>= (left) and =<< (right) operators. Now the operators are in fact simply associative, so this is just a matter of order of evaluation, but I am not sure I see the value of evaluating foldrM as (f a =<< f b) =<< f c z, rather than as f a =<< (f b =<< f c z).
Why would that be a factor in deciding whether the accumulator should be strictly evaluated? We should associate the monadic binds in the most efficient way for each strictness. Now a user would be wise to choose carefully between foldlM and foldrM, and choose the appropriate strictness, but what is the reason for your left/yes, right/no dichotomy?
It seems to me that a more strict foldrM' is reasonable if it helps to noticeably reduce the constant factors in unavoidable linear cost of a foldrM in a strict monad. So that should not be at all controversial. That gives you the
What remains to decide is how to express the two strictness variants. I think the “naive” version may be a reasonable candidate for the non-strict version at least.
Thus perhaps:
foldrM f = foldr ((=<<) . f) . pure
foldrM' f = foldr (\x r -> r >>= f x >>= (pure $!)) . pure
Dunno, maybe I’ll find it in me to fight another bureaucracy battle, but not right now. It’s also quite a non-trivial amount of work to determine which versions are best and how to convince folks that they are.
That’s literally the opposite to what the Haddock says, given that >=> is infixr and do-notation elaborates accordingly?
Am I crazy or is that Haddock plain wrong on how >>= ends up associating?
Free is one example. The latter turns a linear algorithm over Free into a quadratic one.
This includes any Free-like constructions like streaming or fancy handling of ASTs or naive extensible effects or I just about any sort of tree that happens to be a monad.
Because you want your definition to either be a good consumer or a good producer (or both when possible). A strict fold associating to the left tends to be a good consumer. A lazy fold associating to the right tends to be a good producer. If you don’t follow that rule, you end up with nearly useless garbage like foldl or concatMapM.
(if someone wants to be pedantic, yes, for left-nested structures the rules are the opposite, go introduce a bunch of left-nested structures into your project and use generic functions over them if you feel like the situation isn’t annoying enough already)
I don’t feel like it’s the best one, but I do agree that it’s a reasonable candidate. Certainly better than what we have there right now.
Yes, I’m an idiot, it already associates to the right in foldrM. The Haddock is correct. My understanding that it was associating to the left is what was incorrect.
Well, then the definition in base isn’t as bad as I thought it was.
The associativity situation with fold[lr]M is a bit more subtle, because we have into account both how the values are associated, and how the effects are associated.
With foldrM effects necessarily propagate from the tail of the list towards the front, unless the monad is lazy (most aren’t) or, in any case, with the definition as in base, foldrM diverges for infinite lists, which is rather different from a non-monadic right fold.
And yet, at the value level, it looks like a right fold.
So the usual heuristics may not quite carry over.
Are you willing to be pedantically explicit about what behaviour you expect. What is the expected evaluation tree?
foldrM f z [a, b, …, y] ?=
foldlM f z [a, b, …, y] ?=
foldrM f z t = f y >=> f x >=> ... >=> f b >=> f a $ z
which happens to match the implementation, given that (>=>) is right-associative, but, when I wrote that documentation, I did not intend to imply a particular order of evaluation. I think you’re saying it should be:
foldrM f z t = (...((f y >=> f x) >=> ... ) >=> f b) >=> f a $ z
which woud then match my “naïve” proposal? And you’d also like to see a foldrM' that is strict in the value accumulator?
Would you then also want:
foldlM f z t =
flip f a >=> (flip f b >=> (... >=> (flip f x >=> flip f y))...) $ z
And a corresponding strict in the accumulator version?
Yes. I’ve investigated this a bit more, got some rather surprising results and decided to create a CLC issue. Thank you for encouraging me to do that.
No, as I said in my previous message starting with “Yes, I’m an idiot” , I was wrong. I’ll write down exactly what I believe foldrM should be in the CLC issue that I’m gonna create (I’ll probably create two different ones).
Thank you for asking. I’m completely swamped with various issues, work-related and otherwise and it looks like I won’t be able to fulfill my promise any time soon. Sorry.