I’m working on a file parser/decompressor for so-called CBF files. The repo is at cbf-hs on GitHub.
The file structure is pretty simple: there is an ASCII header part, then an empty line and then there’s a compressed binary blob afterwards (the repo contains an example file in the test-data/ repository):
###CBF: VERSION 1.5, CBFlib v0.7.8 - PILATUS detectors
some ASCII blabla
<binary data here>
I’m parsing the first part with attoparsec, leaving me with the binary stuff in a LazyByteString. The bytes decompress into a list of signed integers, representing pixels in an image. This I’m parsing with Data.Binary. See here. I hope the format is pretty self-explanatory - the Haskell code is basically a word-for-word translation of the official explanation of the format.
And it works and the code is nicely readable. However, it is extremely slow. Parsing a cbf file takes around 5s. In my opinion, it should be in the order of milliseconds instead.
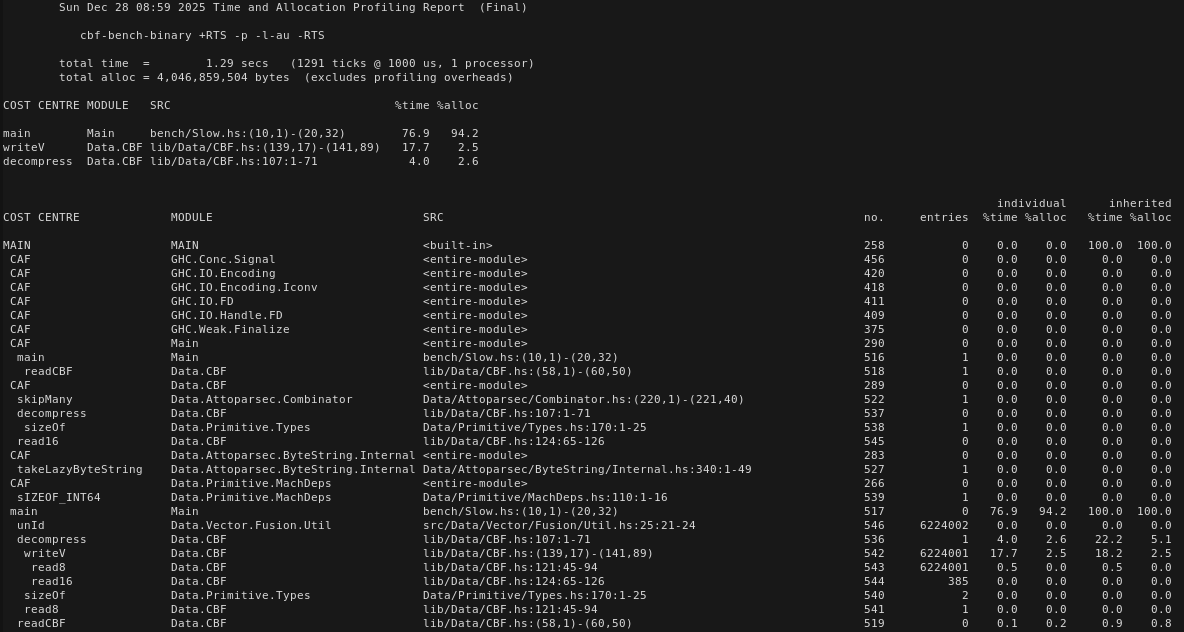
I’ve tried enabling profiling, running with -p and looking at the .prof file. But all it says is that my decompressBinaryBSL function takes up all the runtime. This is not helpful. And I’m not sure how to proceed further with this.
Is using Binary plus lazy bytestrings even a good idea for such a stateful decompressor?
If you want to try it out, cloning the repo and running cabal run cbf-bench-binary should work (it outputs the difference between the Haskell-decompressed data and the decompressed data from the CBF reference implementation).
Attoparsec isn’t great for this. Death by many allocations - 2GB of heap space for a 20MB file. My guess is the only reason decompressBinaryBSL shows up in your profile so much is because the work is deferred till then.
According to event log decomprssBinaryBSL most of its time doing takeLazyByteString (from attoparsec) and pappend (also from AttoParsec). So the problem is really your attoparsec logic but I’ll have to spend more time with it to get a sense of what’s wrong.
Edit: not that attoparsec isn’t great but it’s easy to shoot yourself in the foot and it’s hard to think about performance - for me at least. For my Parquet implementation (also a binary format) I ended up rolling my own parsing.
It’s all binary’s fault but it doesn’t show up in the trace. Weird.
The culprit indeed seems to be binary as you suspected. Writing it by hand is a lot faster:
uncons1 :: BSL.ByteString -> Maybe (Int8, BSL.ByteString)
uncons1 bs = do
(x, bs') <- BSL.uncons bs
pure (fromIntegral x, bs')
uncons2 :: BSL.ByteString -> Maybe (Int16, BSL.ByteString)
uncons2 bs = do
(x,bs') <- BSL.uncons bs
(y,bs'') <- BSL.uncons bs'
pure (fromIntegral x + fromIntegral y * 0x100, bs'')
uncons4 :: BSL.ByteString -> Maybe (Int32, BSL.ByteString)
uncons4 bs = do
(x,bs') <- uncons2 bs
(y,bs'') <- uncons2 bs'
pure (fromIntegral x + fromIntegral y * 0x10000, bs'')
uncons8 :: BSL.ByteString -> Maybe (Int64, BSL.ByteString)
uncons8 bs = do
(x,bs') <- uncons4 bs
(y,bs'') <- uncons4 bs'
pure (fromIntegral x + fromIntegral y * 0x100000000, bs'')
decompressBinary :: Int -> Int64 -> BSL.ByteString -> [Int64]
decompressBinary !0 !currentValue bs = []
decompressBinary !maxValuesConsumed !currentValue bs = do
case uncons1 bs of
Nothing -> [] -- fail
Just (delta8, bs1)
| -127 <= delta8 && delta8 <= 127 ->
let !newValue = currentValue + fromIntegral delta8
in newValue : decompressBinary (maxValuesConsumed - 1) newValue bs1
| otherwise ->
case uncons2 bs1 of
Nothing -> [] -- fail
Just (delta16, bs2)
| -32767 <= delta16 && delta16 <= 32767 ->
let !newValue = currentValue + fromIntegral delta16
in newValue : decompressBinary (maxValuesConsumed - 1) newValue bs2
| otherwise ->
case uncons4 bs2 of
Nothing -> [] -- fail
Just (delta32, bs3)
| -2147483647 <= delta32 && delta32 <= 2147483647 ->
let !newValue = currentValue + fromIntegral delta32
in newValue : decompressBinary (maxValuesConsumed - 1) newValue bs3
| otherwise ->
case uncons8 bs2 of
Nothing -> [] -- fail
Just (delta64, bs4) ->
let !newValue = currentValue + fromIntegral delta64
in newValue : decompressBinary (maxValuesConsumed - 1) newValue bs4
This works as long as you don’t really care that much about failure. This code just stops and returns [] after the failure point. Using Maybe instead will break the guarded recursion and thus make it less nice for laziness, but maybe that will still be faster than using the Get.
Note that your reference implementation also uses binary which is the next bottleneck.
Edit: Also, I see this code is broken. I need to investigate further.
I’m not sure how to use it. It works on strict byte strings, and I don’t want to read the full file into memory. I also cannot easily work on the chunks, since decompression crosses chunk boundaries.
Your code uses BSL.length, which has to traverse the entire lazy ByteString, so apparently you already read the full file into memory. One should rather use BSL.compareLength, it’s faster and lazier.
I’ve taken a look but haven’t found anything that could potentially speed it up, but I did find something in the specification that caught my eye. The “byte_offset” decompression algorithm states in step 8 to read an Int32then an Int64 to make it delta. But I notice that neither decompressBinary nor decompressSingleChunk do this and have no difference to the target file (benchmarks show up as []). What is happening here?
Okay came back and gave this a better look since it bubbled up again. I changed
@Bodigrim I think you’re right with this. @pmidden I get a significant performance improvement when I switch to strict bytestrings and I think it’s because the indexMaybe function for lazy bytestrings is expensive (so is drop but that’s not in the hot path).
The runtime on my machine is ~7 seconds. The hot path seems to be read8 → writeV. The most significant work happening in read8 is the indexing - which for lazy bytestrings isn’t constant time.
Solution
Switched to strict bytestrings to get constant time indexing (converted back to lazy for the other reads). Also that extra allocation wrapping read8 in a Just probably isn’t helping and isn’t necessary (since you already do the bytestring bounds check in the outer conditional). Also since you do a bounds check on the vector before writing you can do an unsafewrite.
decompressST :: Int -> BSL.ByteString -> ST s (V.Vector Int64)
decompressST numberOfElements s = do
mutableVector <- MV.new numberOfElements
_ <- decompressSingleChunk (BSL.toStrict s) mutableVector 0 0 0
V.freeze mutableVector
decompress :: Int -> BSL.ByteString -> V.Vector Int64
decompress numberOfElements s = runST (decompressST numberOfElements s)
decompressSingleChunk ::
BS.ByteString ->
MV.STVector (MV.PrimState (ST s)) Int64 ->
Int ->
Int ->
Int64 ->
ST s ()
decompressSingleChunk !s !mutableVector !outPos !inPos !value = do
if inPos >= BS.length s - 1
then pure ()
else do
let readInt8 :: Int -> Int64
readInt8 !p = {-# SCC "read8" #-} fromIntegral (unsafeCoerce (BS.index s p) :: Int8)
readInt16 :: Int -> Maybe Int64
readInt16 !p
| p < BS.length s - 2 = Just $ {-# SCC "read16" #-} fromIntegral (runGet getInt16le (BS.fromStrict $ BS.drop p s))
| otherwise = Nothing
readInt32 :: Int -> Maybe Int64
readInt32 !p
| p < BS.length s - 4 = Just $ {-# SCC "read32" #-} fromIntegral (runGet getInt32le (BS.fromStrict $ BS.drop p s))
| otherwise = Nothing
readInt64 :: Int -> Maybe Int64
readInt64 !p
| p < BS.length s - 8 = Just $ {-# SCC "read64" #-} fromIntegral (runGet getInt64le (BS.fromStrict $ BS.drop p s))
| otherwise = Nothing
recurse _bitDepth !newInPos !d = do
if outPos >= MV.length mutableVector
then pure ()
else
{-# SCC "writeV" #-}
do
MV.unsafeWrite mutableVector outPos (value + d)
decompressSingleChunk s mutableVector (outPos + 1) newInPos (value + d)
!delta8 = readInt8 inPos
if -127 <= delta8 && delta8 <= 127
Now read8 is much faster and has no intermediate allocations.
So in general avoiding allocations and being clear about the time complexity of the different functions helps when doing byte level stuff.
I tried to compare what Data.Binary does when decoding things to compare with @jaror’s findings but I didn’t quite understand the data flow in the code base.
Can you cross check that this is true on your machine?
Okay. I didn’t like the “discard laziness altogether” approach. So I thought about it again - if the problem is lazy bytestring doing these linear indexing/reading functions then it probably would also help performance if we kept the laziness but stopped using the position to index the variable and instead consumed the bytestring linearly.
Rewrote it to not nest quite as much and this does cut performance but not as much as having a strict bytestring (it’s still twice as slow as a strict bytestring and I’m not sure why) - but laziness might help you for very large files so it’s worth improving the lazy approach.
decompressSingleChunk ::
BSL.ByteString ->
MV.STVector (MV.PrimState (ST s)) Int64 ->
Int ->
Int64 ->
ST s ()
decompressSingleChunk !s !mutableVector !outPos !value
| outPos >= MV.length mutableVector = pure ()
| otherwise = case readDelta s of
Nothing -> pure ()
Just (!d, !rest) -> do
{-# SCC "writeV" #-} MV.unsafeWrite mutableVector outPos (value + d)
decompressSingleChunk rest mutableVector (outPos + 1) (value + d)
readDelta :: BSL.ByteString -> Maybe (Int64, BSL.ByteString)
readDelta bs = do
(!b, !rest1) <- BSL.uncons bs
let !delta8 = fromIntegral (fromIntegral b :: Int8) :: Int64
if -127 <= delta8 && delta8 <= 127
then pure (delta8, rest1)
else readDelta16 rest1
where
readDelta16 !rest1 = do
(!delta16, !rest2) <- {-# SCC "read16" #-} runGetMaybe getInt16le rest1
if -32767 <= delta16 && delta16 <= 32767
then pure (fromIntegral delta16, rest2)
else readDelta32 rest2
readDelta32 !rest2 = do
(!delta32, !rest3) <- {-# SCC "read32" #-} runGetMaybe getInt32le rest2
if -2147483647 <= delta32 && delta32 <= 2147483647
then pure (fromIntegral delta32, rest3)
else readDelta64 rest3
readDelta64 !rest3 = do
(!delta64, !rest4) <- {-# SCC "read64" #-} runGetMaybe getInt64le rest3
pure (delta64, rest4)
runGetMaybe :: Get a -> BSL.ByteString -> Maybe (a, BSL.ByteString)
runGetMaybe !g !bs = case runGetOrFail g bs of
Left _ -> Nothing
Right (!rest, _, !v) -> Just (v, rest)
I just threw a bunch of bangs in there. Some of them might not make much of a difference.
-32767 <= delta16 && delta16 <= 32767 is equivalent to delta16 == -32768. Which is equivalent to BSL.takeWhile (== -128) bs == 2. And same elsewhere. Could this be used to simplify things?
The binary package is known ( store: a new and efficient binary serialization library ) to be much, much slower than what Haskell can do ( serialization/report.md at master · haskell-perf/serialization · GitHub ). Mostly it’s due to allocations which are necessary due to binary’s design. Years ago I once asked the library maintainers to change the statement on the package from “suitable for high performance scenarios” to something more realistic like “a solid reference implementation, but not efficient with respect to other options, like cbor, flatparse, attoparsec.” I think they agreed, but for whatever reason it didn’t make it in. So the scenario of people writing high performance things with binary and finding it’s really slow happens often.
Comparatively, flatparse was on par with Rust’s nom in one like-for-like benchmark I conducted a few years ago. I can dig that up if skeptical, but it stands to reason, the libraries make different trade offs.
I’ve audited the binary package when I was a consultant, and it was solid correctness-wise. But in my head it sits in a “correct but slow” box, alongside options making different trade offs with better perf.
I’ve managed to fix my code and pushed it to my fork:
On my machine, it improves the running time of the cbf-bench-binary from 2.284s to 0.288s, so almost 8x. It also reduces memory residency from 534MB to 24MB which is about 22x less and suggests it runs in constant additional memory.